
1 Introdução
O Apache Spark é um mecanismo de análise unificado de código fonte aberto para computação distribuída, processamento de dados em grande escala.
Falando um pouco sobre sua história, o Spark foi desenvolvido em um laboratório da Universidade da Califórnia e posteriormente repassado para a Apache, que o mantém até os dias de hoje.
APIs de alto nível em Java, Scala,Python e R são fornecidas pelo Spark, que disponibiliza uma interface para programação de clusters com paralelismo e tolerância a falhas.
Possui módulos integrados para SQL e processamento de dados estruturados,machine learning para aprendizado de máquinas, processamento de gráficos e, não menos importante, streaming estruturado para computação incremental e processamento de fluxo.
2 Desenvolvimento
Visão geral do Apache Spark
O Spark suporta ampla gama de cargas de trabalho, sendo algumas das principais:
- Machine Learning;
- Análise Interativa;
- Batch Application;
- Algoritmos Interativos;
- Business Inteligence.
É possível, utilizando o Spark, processar dados de diferentes fontes,como por exemplodo HDFS, AWS S3, Databricks(DBFS) e Blob Azure. Normalmente é utilizado em conjunto com o Flume ou Kafka.

O ecossistema Spark possui cinco componentes principais, sendo eles:
1. O Spark Streaming oferece a capacidade de processar dados à medida em que os dados estão sendo gerados, facilitando a criaçãode soluções de streaming escalonáveis e tolerantes a falhas.
É fornecido uma API integradaà linguagem Spark para o processamento de stream, para que você possa escrever jobs de streaming da mesma forma que os jobs em lote, porém via streaming, o Spark fornece recursos de processamento de dados quase que em tempo real. O Spark Streaming oferece suporte a Java, Scala e Python.
2. Spark SQL é um módulo disponível dentro do próprio Spark para trabalhar com dados estruturados que oferece suporte a uma maneira comum de acessar uma variedade de fontes de dados.
Ele permite consultar dados estruturados dentro de programas Spark, permitindo assim que possamos interagir com o Spark SQL, usando SQL ou Dataset API.
O Spark SQL permite o acesso a armazenamentos existentes do Apache Hive, permitindo leituras e escritas, porém é necessário configurar o recurso para usufruir dessa funcionalidade. O modo de servidor fornece conectividade padrão por meio de conectividade de banco de dados Java ou conectividade aberta de banco de dados.
Também é possívelutilizar linha de comando ou ODBC/JDBC. O Spark SQL faz otimizações extras usando as informações coletadas.
3. MLlib é a biblioteca de machine learning escalonável do Spark com ferramentas que tornam o machine learning prático, escalonável e fácil. ML lib possui diversos algoritmos de aprendizado comuns, como regressão, classificação e recomendação por exemplo.
Também contém fluxos de trabalho e outros utilitários, incluindo transformações de recursos, construção de pipeline de machine learning, avaliação de modelo e estatísticas.
4. GraphX é a API Spark para gráficos, é flexível e funciona perfeitamente com gráficos. Extrai, transforma, carrega, analisa,e constrói computação gráfica iterativa em um sistema.
Além de uma API altamente flexível, GraphX vem com uma variedade de algoritmos de gráfico. Assim como os demais componentes do Spark, permitea tolerância a falhas e a facilidade de uso do Spark.
5. O Spark Core é um mecanismo de processamento de dados distribuído de uso geral. O Spark Core é a base de todo um projeto, levando em consideração que todas as demais bibliotecas do Spark podem ser utilizadas juntas em um único aplicativo. O mecanismo Core realiza a distribuição de tarefas, programação e funcionalidades.
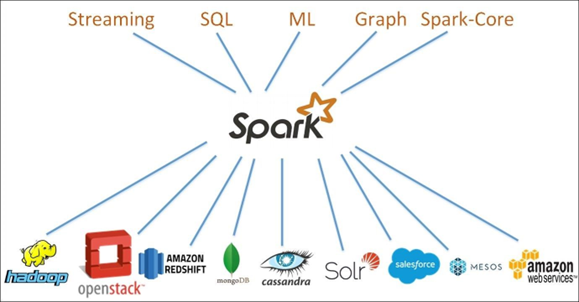
Como o Apache Spark deve ser utilizado?
Os códigos Spark podem ser escritos em Python, Scala ou Java. A console do Spark é chamada de Spark Shell, é interativa para learning e exploração de dados.
O chamado Spark Application consiste em um ou mais Jobs, permitindo o suporte ao processamento de dados em grande escala. Cada job consiste em uma ou mais tasks. Observação: cada Spark Application possui um Spark Driver.
Quando falamos sobre execução, o Spark possui dois modos:
· Client – Driver executado diretamente no cliente, onde não passa pelo Resource Manager.

· Cluster – Driver executado no Application Master passando pelo Resource Manager (Em modo Cluster, caso o cliente desconectar, o application continuará em execução).

É necessário utilizar o Spark corretamente para que o que os serviços interligados como o Resource Manager possam identificar a necessidade de cada execução, provendo o melhor desempenho. Sendo assim cabe ao desenvolvedor saber qual será a melhor maneira de rodar seus jobs Spark, estruturando a chamada realizada e para isso é possível estruturar e configurada forma que quiser os executores Spark.
Osjobs Spark usam principalmente, memória, portanto, é comum realizar ajustes nos valores de configuração do Spark para executores de nó de trabalho. Dependendo da carga de trabalho do Spark, é possível determinar que determinada configuração não padrão do Spark proporcione execuções mais otimizadas. Para isso testes de comparação devem ser efetuados entre as várias opções disponíveis de configuração e entre a própria configuração padrão do Spark.
Informações adicionais:
· YARN (Resource Manager) – É o gerenciador de recursos que serão utilizados em algum processo.O YARN controla a soma máxima de memória usada por todos os contêineres em cada nó do Spark.
· Application Master – É ativado quando alguma execução é iniciada. Os nodes são percorridos para verificar quais atenderão melhor a demanda no momento. Após isso, o Application Master retorna à informação para o Resource Manager e negocia os recursos para realizar a execução.
· Interface do usuário – Fonte de informações sobre recursos usados pelos executores do Spark, os Executores mostram as exibições de Resumo e Detalhe da configuração e dos recursos consumidos.
Spark-submit
É um código que permite a execução de aplicações em Cluster, que fica localizado no diretório bin doSpark.
Para utilizar o spark-submit, alguns parâmetros devem ser passados, são eles:
–class = Entry point do application;
–master = Endereço (URL)do master
–deploy-mode = Modo como será executado (Cluster/Client)
–conf = Chave/Valor (se necessário)
–executor-memory = Velocidade
–executor-cores = Grau de tarefa de paralelismo
Exemplo:
./bin/spark-submit –class org.apache.spark.exemples.Spark
–master yarn
–deploy-mode cluster
–driver-memory 8g
–executor-memory 4g
–executor-cores 2
–queuethequeue exemplo_spark.jar


